Extract Tables from PDF file in a single line of Python Code

How to extract and convert tables from PDFs into Pandas Dataframe using Camelot
A standard principle in data science is that the presence of more data leads to training a better model. Data can be present in any format, data collection and data preparation is an important component of a model development pipeline. The required data for any case study can be present in any format, and it’s the task of the data scientist to get the data into the desired format to proceed with the data preprocessing and other components of the pipeline.
A lot of structured/semi-structured or unstructured data can be present in tabular format in text-based PDF documents and in image format. Developing a custom table extraction model requires a lot of time and effort. In this article, we will discuss how to use an open-source library Camelot, to extract all available tables from PDF documents in just one line of Python Code.
What is Camelot?
Camelot is an open-source Python library, that enables developers to extract all tables from the PDF document and convert it to Pandas Dataframe format. The extracted table can also be exported in a structured form as CSV, JSON, Excel, or other formats, and can be used for modeling.
Camelot has a limitation as it only works with text-based PDFs and not the scanned documents.
How does Camelot work?
Camelot uses two table parsing techniques, i.e Stream and Lattice to extract tables from PDF documents. One can choose between the two table parsing technique.
Stream:
Stream is a parsing technique that uses PDFMiner’s functionality to group characters into words or sentences based on white spaces or margins. Stream parsing techniques are like a guessing-based technique.
Lattice:
Lattice is another parsing technique that does not rely on guessing but finds the horizontal and vertical lines in the table to parse over multiple tables in the PDF document. Lattice can only parse through the tables having demarcated lines between cells. Lattice Algorithm steps to find the tables in the PDF documents are:
- Convert the PDF document into Image using Ghostscript.
- OpenCV-based Morphological transformations are applied to get the horizontal and vertical line segments of the tables in the converted Image.
- Line Intersections are then detected by taking AND of line segments (from point 2) and tables pixel intensities.
- Tables borderline are detected by taking OR of line segments (from point 2) and their pixel intensities.
- Spanning cells or merged cells are detected by using the line intersection and line segments.
- The detected line segments and borderlines of the tables are then scaled and mapped to the PDF document, as the dimensions in the image and PDF may vary.
- After placing the line segments and borderlines of the tables in the appropriate (x, y) coordinates, words found on the cells of the table are detected and mapped to the data frame.
Installation:
Camelot and Ghostscript can be installed from PyPl using the command:
!pip install "camelot-py[cv]"
!apt install python3-tk ghostscriptAfter installation, Camelot can be imported using:
import camelotUsage:
After importing the necessary modules, read the PDF file using camelot.read_pdf() function.
tables = camelot.read_pdf('table.pdf')By default Camelot, only parses through the first page of the pdf document, to parse through the tables present in multiple pages of the document, use pages parameter in read_pdf function.
# pass comma seperated page numbers or page ranges
tables = camelot.read_pdf('table.pdf', pages='1,2,3,5-7,8')Camelot can also extract tables from the password-protected PDF document, just bypassing the required password.
tables = camelot.read_pdf('table.pdf', password='*******')camelot.read_pdf is the only single line of Python code, required to extract all tables from the PDF file. All the tables are now extracted in Tablelist format and can be accessed by its index.
#Access the ith table as Pandas Data frame
tables[i].dfTo export the table to the desired format, you can use camelot.export() function, and use parameter f=’csv’, f=’excel’, f=’html’, or f=’sqlite’ .
tables.export('name.csv', f='csv')To get the parsing report or metric report about how well the data is extracted
tables[i].parsing_report# Output:
{'accuracy': 99.27, 'order': 1, 'page': 1, 'whitespace': 13.89}Code:
The PDF document used in the below illustration is downloaded from Table, Table1.
In [1]:
!apt install python3-tk ghostscript
!pip install "camelot-py[cv]"
import camelotIn [2]:
tables = camelot.read_pdf('table.pdf')
tablesOut[1]:
<TableList n=1>In [3]:
tables[0].parsing_reportOut[2]:
{'accuracy': 99.27, 'order': 1, 'page': 1, 'whitespace': 13.89}In [4]:
tables[0].dfOut[3]:
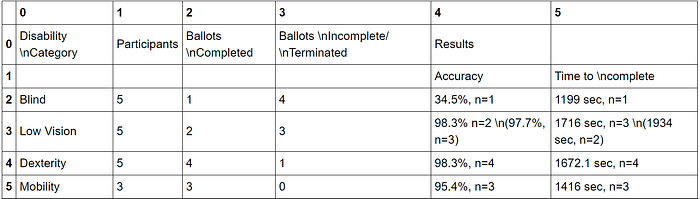
In [5]:
tables1 = camelot.read_pdf('table1.pdf')
tables1Out[4]:
<TableList n=2>In [6]:
tables1[0].parsing_reportOut[5]:
{'accuracy': 100.0, 'order': 1, 'page': 1, 'whitespace': 0.0}In [7]:
tables1[0].dfOut[6]:
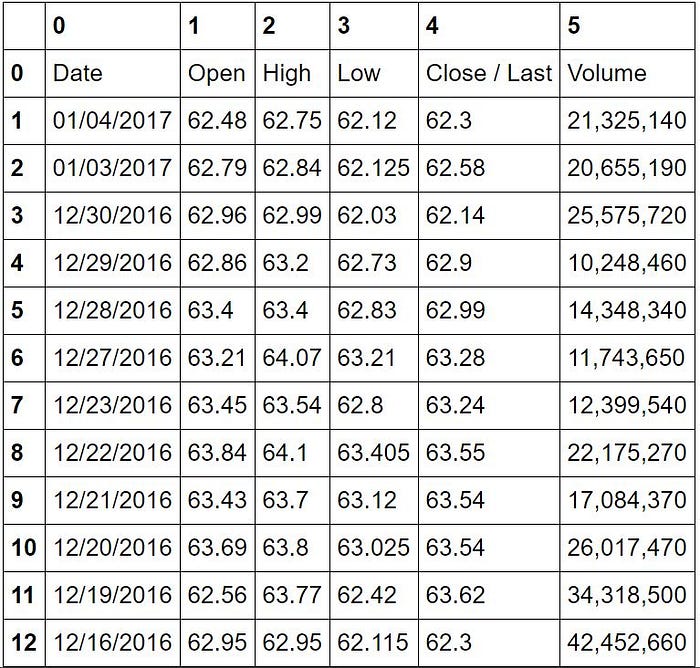
In [8]:
tables1[1].dfOut[7]:
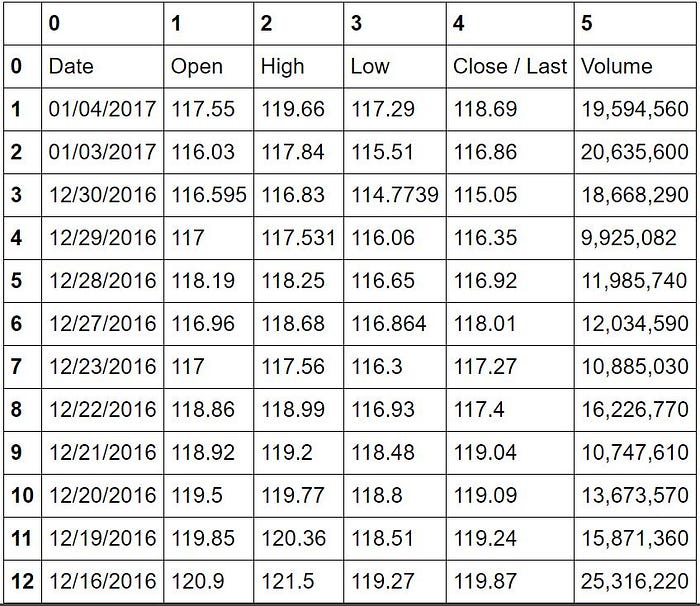
Conclusion:
In this article, we have discussed how to extract tables from PDF documents and convert them to Pandas Dataframe which can be further used for modeling. There are various open-source libraries including Tabula, pdftables, pdf-table-extract, pdfplumber that provide similar functionality as Camelot.
Camelot works better than its alternatives, read this article to get a comparison of results between Camelot and its competitor’s libraries.
References:
Camelot Documentation: https://camelot-py.readthedocs.io/en/master/
